Tomorrow morning at 7:30 AM I will be leaving from Monterey for San Francisco where we (me and Michelle) will be catching a flight to Atlanta at noon. We will arrive in Atlanta around 8:00 PM EST. I believe we will have the shortest day ever due to the time difference.
I am really thankful to MySQL and especially Arjen and Jay for inviting me to speak at the MySQL Users Conference. I enjoyed it a lot and will miss everyone I met until we meet again. Thank you everyone for such a great time.
Frank
MySQLUC
Saturday, April 29, 2006
Friday, April 28, 2006
Applied Ruby on Rails and AJAX
It's hard to believe that MySQL Users Conference is over. Though each day seemed like very long, it went pretty fast.
My Applied Ruby on Rails and AJAX session was the last session at the MySQL Users Conference and was happening at the same time as Jim Starkey's Falcon storage engine. I was kinda worried about the attendance at first, but when my session started, I saw people standing in the back (full room). A lot of questions were asked at the end. Thanks to everyone who attended.
Harrison Fisk, my session buddy, presented me with a speaker's gift from MySQL, which was a very nice MySQL pen (Thanks).
At the end of the session I was told that there were about 114 people attending my session, roughly the same amount of folks that attended Jim's session, Wow!.
As I was walking out of the ballroom, I ran into Jay Pipes who told me that he was just talking to some people and they said the session was very informative.
I had asked in my session for everyone to give me their business card if they would like to receive a free copy of my book, Pro Rails, as it gets completed. I received many cards, some with very good feedback. If you were at my session, and forgot to give me your business card, you can leave a comment here and I will send you the book once it is ready.
I will be putting the slides online as soon as I am back in Georgia. Currently, I am in Monterey.
I met so many good people at the conference and had a great time socializing. Like Mike says in his post, MySQL Users Conference winds down, the conference had a great social element to it. I will be jotting down the names of friends I met at the conference in a later post.
Overall, it felt so good to meet fellow PlanetMySQL bloggers and the MySQL team.
Jeremy Cole has posted a lot of good photos on his MySQL UC 2006 Gallery, so check it out (Thanks Jeremy).
My Applied Ruby on Rails and AJAX session was the last session at the MySQL Users Conference and was happening at the same time as Jim Starkey's Falcon storage engine. I was kinda worried about the attendance at first, but when my session started, I saw people standing in the back (full room). A lot of questions were asked at the end. Thanks to everyone who attended.
Harrison Fisk, my session buddy, presented me with a speaker's gift from MySQL, which was a very nice MySQL pen (Thanks).
At the end of the session I was told that there were about 114 people attending my session, roughly the same amount of folks that attended Jim's session, Wow!.
As I was walking out of the ballroom, I ran into Jay Pipes who told me that he was just talking to some people and they said the session was very informative.
I had asked in my session for everyone to give me their business card if they would like to receive a free copy of my book, Pro Rails, as it gets completed. I received many cards, some with very good feedback. If you were at my session, and forgot to give me your business card, you can leave a comment here and I will send you the book once it is ready.
I will be putting the slides online as soon as I am back in Georgia. Currently, I am in Monterey.
I met so many good people at the conference and had a great time socializing. Like Mike says in his post, MySQL Users Conference winds down, the conference had a great social element to it. I will be jotting down the names of friends I met at the conference in a later post.
Overall, it felt so good to meet fellow PlanetMySQL bloggers and the MySQL team.
Jeremy Cole has posted a lot of good photos on his MySQL UC 2006 Gallery, so check it out (Thanks Jeremy).
Thursday, April 27, 2006
Technorati: Scaling the real time web
I am sitting in Dorion's session about scaling the real time web. Technorati tags grew from 0 to 100 million in a year.
Technorati has about 10TB of core data in MySQL over about 20 machines and they use replication. With replication they add 100TB and 200 machines more. Currently growing at about 1TB per day in total.
A service oriented architecture to separate physical and logical access is used. Technorati uses commodity hardware and Open Source software.
Scaling Technorati Tags : Launched on Janurary 10 of 2005.
Tags are partitioned by entity (tags and posttags). Tags database is separate. Post information in one set of databases and tags information in another set of databases. A caching layer is also present. Overtime Technorati has blended the use of InnoDB and MyISAM based on use.
Currently around 120 million tags in a single table distributed using replication.
100 million records (tags) is where they start thinking of diving the data in multiple tags.
At this point they are processing half a million post tags a day.
A lot of writes (more than queries).
Release early release often.
Get feedback
Fix it fast
move on
In January 05: 1 master , 1 standby
March 05, 1 master, 1 standby
2 InnoDB query slaves
Jun 05, 1 master 1 standby
3 MyISAM query slaves
Sep 05 1 master 1 standby
6 MyISAM query slaves
Jan 06
1 master, 1 standby
6 MyISAM query slaves
3 MyISAM async count slaves
saving...
MyISAM vs InnoDB.
InnoDB is the right choice for Master-class DBs (data integrity is crucial and write loads are high)
MyISAM right choiice for GROUP BY queries and for read-mostly applications.
Partitioning:
Partition data by various dimensions: Time, Key, Entity, Random key, Finxed vs Variable length.
If you do entity partition (separate posts and tags in different databases) the drawback is that you cannot do joins.
Master database is called cosmos.
Partitioning at Technorati
Technorati uses all of these partitions and also uses some in combionation.
The Cosmos DB is used for the entire blogosphere.
ID based using mod to allocate to shard
Entity based to organize commonly queried lookup tables in one location
Entity based but ID range partitioned.
TIme based for reporting data (hourly or daily). Every web hit is logged. Hourly tables are switched to daily tables. Time based partitioning is really important to Technorati. The hot front end needs to be on better faster hardware.
Examples of Partitioning.
Main data set is sharded by Blog ID with a central sequence generation and map.
Currently running MySQL 4.0 and 4.1. Not ready to jump to 5.0 (being used in a playground).
Replication is ennential to distribute query load and provide for redundancy.
Type of replication used is Master -> Master -> Slave to distribute common lookup tables.
A new slave is bootstrapped using mysqldump.
Technorati has 200+ instances of MySQL and they need to know if they're all happy. To do this they create a management DB and use a heartbeat table and record state in management DB. To this they have put a web front end with sorting and filtering.
MySQL is used to manage meta-data.
Jeremy Zawodny's book has chapter on heartbeat tables.
Overall a good session.
MySQLUC
Technorati
Technorati has about 10TB of core data in MySQL over about 20 machines and they use replication. With replication they add 100TB and 200 machines more. Currently growing at about 1TB per day in total.
A service oriented architecture to separate physical and logical access is used. Technorati uses commodity hardware and Open Source software.
Scaling Technorati Tags : Launched on Janurary 10 of 2005.
Tags are partitioned by entity (tags and posttags). Tags database is separate. Post information in one set of databases and tags information in another set of databases. A caching layer is also present. Overtime Technorati has blended the use of InnoDB and MyISAM based on use.
Currently around 120 million tags in a single table distributed using replication.
100 million records (tags) is where they start thinking of diving the data in multiple tags.
At this point they are processing half a million post tags a day.
A lot of writes (more than queries).
Release early release often.
Get feedback
Fix it fast
move on
In January 05: 1 master , 1 standby
March 05, 1 master, 1 standby
2 InnoDB query slaves
Jun 05, 1 master 1 standby
3 MyISAM query slaves
Sep 05 1 master 1 standby
6 MyISAM query slaves
Jan 06
1 master, 1 standby
6 MyISAM query slaves
3 MyISAM async count slaves
saving...
MyISAM vs InnoDB.
InnoDB is the right choice for Master-class DBs (data integrity is crucial and write loads are high)
MyISAM right choiice for GROUP BY queries and for read-mostly applications.
Partitioning:
Partition data by various dimensions: Time, Key, Entity, Random key, Finxed vs Variable length.
If you do entity partition (separate posts and tags in different databases) the drawback is that you cannot do joins.
Master database is called cosmos.
Partitioning at Technorati
Technorati uses all of these partitions and also uses some in combionation.
The Cosmos DB is used for the entire blogosphere.
ID based using mod to allocate to shard
Entity based to organize commonly queried lookup tables in one location
Entity based but ID range partitioned.
TIme based for reporting data (hourly or daily). Every web hit is logged. Hourly tables are switched to daily tables. Time based partitioning is really important to Technorati. The hot front end needs to be on better faster hardware.
Examples of Partitioning.
Main data set is sharded by Blog ID with a central sequence generation and map.
Currently running MySQL 4.0 and 4.1. Not ready to jump to 5.0 (being used in a playground).
Replication is ennential to distribute query load and provide for redundancy.
Type of replication used is Master -> Master -> Slave to distribute common lookup tables.
A new slave is bootstrapped using mysqldump.
Technorati has 200+ instances of MySQL and they need to know if they're all happy. To do this they create a management DB and use a heartbeat table and record state in management DB. To this they have put a web front end with sorting and filtering.
MySQL is used to manage meta-data.
Jeremy Zawodny's book has chapter on heartbeat tables.
Overall a good session.
MySQLUC
Technorati
More Photos from the Quiz Show
Some of the photos here are kinda dark but they give the idea.

The Procasti Nation team (Sheeri missing)

Brian and Monty auctioning the T-Shirt

Monty holding the T-Shirt

Monty models the T-Shirt

From left to right (Monty, Me and Brian Aker)
Many more photos to come so stay tuned.
MySQLUC

The Procasti Nation team (Sheeri missing)

Brian and Monty auctioning the T-Shirt

Monty holding the T-Shirt

Monty models the T-Shirt

From left to right (Monty, Me and Brian Aker)
Many more photos to come so stay tuned.
MySQLUC
MySQL Users Conference: What a Quiz Show!

Wow, just got out of a very interesting quiz show at the MySQL Users Conference which took an interesting turn.
Near the end of the quiz show, Arjen announced that the T-shirt signed by all MySQL conference speakers (including me) would be auctioned and the proceeds donated to EFF.
My highest bid was $34 at which my wife was looking at me.
Ronald and Sheeri had other plans. They kept outbidding each other for most part.
Arjen, Monty and Brian kept encouraging the audience to go higher and higher.
Sheeri was very excited once Brian announced that he will create a SHOW CONTRIBUTORS command in MySQL and add the winning bidders name to it. Earlier Brian had shown us how to add custom SHOW commands but before showing us how to add it to the information schema, the session time ran out. Ronald Bradford has a good write up on the Hackfest session.
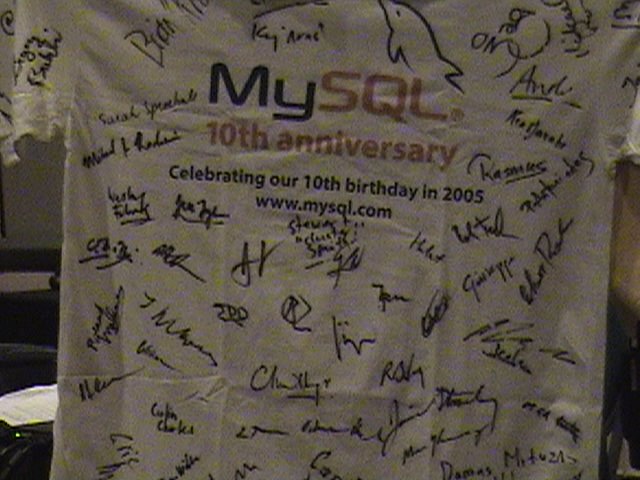
The front of MySQL Users Conference 2006 T-Shirt signed by all speakers.

Back of the T-Shirt that is now with Ronald Bradford.
At one point, Jay had to run and ask VP of MySQL to match the winning amount to be donated to EFF. Jay came back and it was announced that if the auction bid reaches $1000, MySQL will match it up with $800.
Ronald, whose almost all questions were unanswered, finally won the auction for a $1000, followed by Sheeri's bid of $900. Sheeri got the signed Stored Procedures book by Guy Harrison.
A lot of peer pressure was attempted on Jeremy Cole, who kept smiling and as cool as a cucumber. He will be matching 10% of the total.
Going back to the MySQL quiz show, Markus and Beat's team scored higher than our team Procasti nation, organized by Sheeri. Earlier in the morning Markus and Beat had me in their team but Sheeri stole me away at lunch. Our team included Eric Bergen of Yahoo!, Matt Lord of MySQL, Domas Mituzas of MySQL, Oscar Rylin, Sheeri and others.
There was popcorn and pizza served at the quiz show.
It was getting really late so we left.
There was a lot of silly joking and laughing making it a night to remember. I made a movie of some parts of the night and will post it eventually.
Sheeri did say that she didn't want wedding flowers.
Congrats Sheeri and Ronald for getting your name in the MySQL source. After spending so much, you guys deserve it.
Colin Charles also has a write up about the MySQL quiz evening.
MySQLUC
Wednesday, April 26, 2006
Speeding up queries
What an informative session. One of my favorites at the conference.
I am sitting in the session Speeding-up queries by Timour Katchaounov.
Query engine principles
What's new in the 5.0/5.1 engine?
Query engine architecture.
A number of stages in the query engine happen in the parse tree. This is where the SQL standards compliance happens. Access rights are also checked here in Preprocessor. Then we are ready to execute the query in the optimizer.
First are the logical transformations, then cost-based optimization and then plan refinement. Once we have a complete query execution plan, it is sent to query execution component. It uses either table scan or the index scan etc and decides on the various join methods such as nested loops join, hash join etc. Then its passed to the handler API which uses the appropriate storage engine (InnoDB etc).
MySQL uses a left-deep (linear) plan vs. the bushy plan.
Limiting to left-deep (linear) plan, allows to achieve good performance.
QEP (Query Execution Plans) as operator sequences:
For each part, there is table, condition, access and index. Each of these operators contain one variables such as depending on the table. This method of query execution is called pipeline.
It is a nested loop.
1. table = City
Condition = (Population >= 5000000)
Access = Index range scan
index = Population, by (Population >= 5000000)
<>
2. table = Country
condition = (Country.Code = City.Country AND City.ID = COuntry.Capital)
access = Index by unique reference
index = Primary (Code), by (Country.Code = City.Country)
<>
3 table = Languages
condition = (Languages.Country = Country.Code AND Percentage > 4.0)
access = Index by reference
index = Primary (Country, Language), by (Langugaes.Country = Country.code)
Part 1: Query engine principles:
What are the query plans and their execution.
General idea is :
Cost of operations is proportional (~) to disk accesses
A cost unit in MySQL = random read of a data page of 4KB
THe main cost factors include (whats the cost to access the table)
Search all plans in a bottom-up manner.
Depth-first search illustrated:
Suppose we consider tables the way they are mentioned. First languges is joined with Country and then we go back and join with City.
Next we go to table country and expand it with languages and then with city. Next, we go to City. The cost for each possible combination is searched.
New in the 5.0 engine.
If you have more than 5 joins, you may have experienced slowness. To address that greedy optimizer was introduced
"Greedy" join optimizer:
Greedy search (decisions are made on the immediately visible benefit) controls how exhaustive is the search depth. For each serarch step we estimate each potential extension up to search depth. Then the best extension (greedy) is picked and we "forget" the other extensions. Then we continue with the remaining tables.
A drawback / trade off is that we may miss the best plan.
How does greedy search procedure work.
It starts with empty plan and considers all plans with length of 1. and then thinks of all possible ways of adding 1 table. It looks all possible extensions and looks at their cost. The plan with minimum cost is picked.
Then we consider plans of length 2 and so on.
Couple of ways to Controlling the optimizer: Users can influence the index by specifyingm USE INDEX or FORCE INDEX or even IGNORE INDEX. If possible don't use it because some other plan may be better of..
How to control join optimization.
A system variable called optimizer_search_depth can be manipulated. A value of 0 means automatic, 1 means minimal and 62 means maximal. The defauly is now automatic (used to be 62)
Then there is a variable for pruning called optimizer_prune_level 0=> exhaustive, 1=>heuristic(default)
THe third way to force join order is use STRAIGHT_JOIN(you specify the order by specifiying the plan manually (strongly advised not to use it) )
SELECT * ... (Country STRAIGHT_JOIN City) STRAIGHT_JOIN COuntry WHERE ...;
Tables up to 6-7 search depth, the time to optimize is a couple of seconds, then we the search depth is 10, the optimize time is 100 seconds and near 13 search depth, the query compilation time is almost 1000.
Another feature of optimizer: The range optimizer (implemented by Monty).
The range optimizer takes a bookean combination of SARGable conditions. This results in minimal sequence of smallest possible disjoint intervals.
The range optimizer is used for single index and multiple index access and also for partition pruning.
Index merge Union
RowID ordered union. All rows in the index will be returned in RowID order. MySQL goes back and forth to two tables. Everytime it finds a bigger rowID in a different table, it starts adding rows from that table.
Index merge Intersection.
Index scan is done from both tables and each time we do opposite of Index merge union. If the rowId is found in one table and not in another table it is skipped.
Index merge superposition
merge almost any boolean expression. We can combine the above algorithms, so we can intersect first, then merge, and then perform the union.
Loose index scan for GROUP BY / DISTINCT
Another access method to retirve data called Loose index scan for GROUP BY / DISTINCT.
Consider query
SELECT Country, max (POpulation) FROM CIty WHERE Name = 'Sorrento' GROUP by country;
If we execute the query in 4.1 it will perform an index scan considering each possible key in the index then it checks the index and then it groups.
There is a way to execute these queries faster using Loose index scan. First it scans the index, and finds the first key where name is Sorrento and from that record it can find the group of the query (i.e. USA). Once the group prefix 'USA' has been found, it composes a search key <'USA', 'Sorrento'> and then jumps to first key with <'USA', 'Sorrento'>
Find the first tuple in the group,
Add the value for the name key,
compose a search key
and jump to that key so we don't have a need to scan every key.
If we need to find the minimum value, pick the first one. If we want the max, we pick the last one.
This method is applied in a bit more tricky case. Some conditions must be met. First of all teh GROUP BY column must be in front. If there are any query conditions, then those fields should be immediately after the GROUP BY column. Otherwise, this method won't be applied.
Even if we have a DISTINCT clause, the optimizer can still apply this method.
This method offers potentionally x10, x100, etc improvement. There are a few rules of thumb: when this method is good
Given a query over paritioned table, match table DDL against the WHERE clause and find subset of partitions we need to scan to resolve the query.
The internals of partition pruning
We create virtual table definition from partitioning description: (part_field1, ... part_fieldN, subpart_field1,...subpart_fieldN)
Rub Range Analyzer over the WHERE clause and the virtual table definition.
Obtain and interval sequence over virtual table definition.
Suppose we have range [a,b] from 2 to 5. The range optimizer can produce a sequence. We walk through all paritions and we see how it overlaps.
Equality propagation (5.0)
SARGable argument transitive closure
What's coming:
I am sitting in the session Speeding-up queries by Timour Katchaounov.
Query engine principles
What's new in the 5.0/5.1 engine?
Query engine architecture.
A number of stages in the query engine happen in the parse tree. This is where the SQL standards compliance happens. Access rights are also checked here in Preprocessor. Then we are ready to execute the query in the optimizer.
First are the logical transformations, then cost-based optimization and then plan refinement. Once we have a complete query execution plan, it is sent to query execution component. It uses either table scan or the index scan etc and decides on the various join methods such as nested loops join, hash join etc. Then its passed to the handler API which uses the appropriate storage engine (InnoDB etc).
MySQL uses a left-deep (linear) plan vs. the bushy plan.
Limiting to left-deep (linear) plan, allows to achieve good performance.
QEP (Query Execution Plans) as operator sequences:
For each part, there is table, condition, access and index. Each of these operators contain one variables such as
It is a nested loop.
1. table = City
Condition = (Population >= 5000000)
Access = Index range scan
index = Population, by (Population >= 5000000)
<>
2. table = Country
condition = (Country.Code = City.Country AND City.ID = COuntry.Capital)
access = Index by unique reference
index = Primary (Code), by (Country.Code = City.Country)
<>
3 table = Languages
condition = (Languages.Country = Country.Code AND Percentage > 4.0)
access = Index by reference
index = Primary (Country, Language), by (Langugaes.Country = Country.code)
Part 1: Query engine principles:
What are the query plans and their execution.
General idea is :
- assign cost to operations
- assign cost to (partial) plans (not to complete plans)
- search for plans with lowest cost
- query plans are simnple
- there is data statistics and
- there is meta-data
- search space (possible plans): The total set of plans we can search through.
- cost model:
- search procedure
Cost of operations is proportional (~) to disk accesses
A cost unit in MySQL = random read of a data page of 4KB
THe main cost factors include (whats the cost to access the table)
- Data statistics
- number of pages per table (index) - P(R) or (P(I))
- the cardinatily of tables / indexes N(R)
- length of rows and keys
- key distribution
- Schema
- uniqueness (PK)
- nullability
- Simplified cost model of table scan
- cost (access(R)) ~ P(R))
Search all plans in a bottom-up manner.
- which means begin with all 1-table plans and
- for each plan QEP =
- expand QEP with remaining {Tk, ..., Tn} tables
Depth-first search illustrated:
Suppose we consider tables the way they are mentioned. First languges is joined with Country and then we go back and join with City.
Next we go to table country and expand it with languages and then with city. Next, we go to City. The cost for each possible combination is searched.
New in the 5.0 engine.
If you have more than 5 joins, you may have experienced slowness. To address that greedy optimizer was introduced
"Greedy" join optimizer:
Greedy search (decisions are made on the immediately visible benefit) controls how exhaustive is the search depth. For each serarch step we estimate each potential extension up to search depth. Then the best extension (greedy) is picked and we "forget" the other extensions. Then we continue with the remaining tables.
A drawback / trade off is that we may miss the best plan.
How does greedy search procedure work.
It starts with empty plan and considers all plans with length of 1. and then thinks of all possible ways of adding 1 table. It looks all possible extensions and looks at their cost. The plan with minimum cost is picked.
Then we consider plans of length 2 and so on.
Couple of ways to Controlling the optimizer: Users can influence the index by specifyingm USE INDEX or FORCE INDEX or even IGNORE INDEX. If possible don't use it because some other plan may be better of..
How to control join optimization.
A system variable called optimizer_search_depth can be manipulated. A value of 0 means automatic, 1 means minimal and 62 means maximal. The defauly is now automatic (used to be 62)
Then there is a variable for pruning called optimizer_prune_level 0=> exhaustive, 1=>heuristic(default)
THe third way to force join order is use STRAIGHT_JOIN(you specify the order by specifiying the plan manually (strongly advised not to use it) )
SELECT * ... (Country STRAIGHT_JOIN City) STRAIGHT_JOIN COuntry WHERE ...;
Tables up to 6-7 search depth, the time to optimize is a couple of seconds, then we the search depth is 10, the optimize time is 100 seconds and near 13 search depth, the query compilation time is almost 1000.
Another feature of optimizer: The range optimizer (implemented by Monty).
The range optimizer takes a bookean combination of SARGable conditions. This results in minimal sequence of smallest possible disjoint intervals.
The range optimizer is used for single index and multiple index access and also for partition pruning.
Index merge Union
RowID ordered union. All rows in the index will be returned in RowID order. MySQL goes back and forth to two tables. Everytime it finds a bigger rowID in a different table, it starts adding rows from that table.
Index merge Intersection.
Index scan is done from both tables and each time we do opposite of Index merge union. If the rowId is found in one table and not in another table it is skipped.
Index merge superposition
merge almost any boolean expression. We can combine the above algorithms, so we can intersect first, then merge, and then perform the union.
Loose index scan for GROUP BY / DISTINCT
Another access method to retirve data called Loose index scan for GROUP BY / DISTINCT.
Consider query
SELECT Country, max (POpulation) FROM CIty WHERE Name = 'Sorrento' GROUP by country;
If we execute the query in 4.1 it will perform an index scan considering each possible key in the index then it checks the index and then it groups.
There is a way to execute these queries faster using Loose index scan. First it scans the index, and finds the first key where name is Sorrento and from that record it can find the group of the query (i.e. USA). Once the group prefix 'USA' has been found, it composes a search key <'USA', 'Sorrento'> and then jumps to first key with <'USA', 'Sorrento'>
Find the first tuple in the group,
Add the value for the name key,
compose a search key
and jump to that key so we don't have a need to scan every key.
If we need to find the minimum value, pick the first one. If we want the max, we pick the last one.
This method is applied in a bit more tricky case. Some conditions must be met. First of all teh GROUP BY column must be in front. If there are any query conditions, then those fields should be immediately after the GROUP BY column. Otherwise, this method won't be applied.
Even if we have a DISTINCT clause, the optimizer can still apply this method.
This method offers potentionally x10, x100, etc improvement. There are a few rules of thumb: when this method is good
- the logic of choice here is opposite to range scan. (the less selective the index, the better)
- the more keys per group, the better (there will be fewer jumps)
- the index must cover all fields in order
<>
Given a query over paritioned table, match table DDL against the WHERE clause and find subset of partitions we need to scan to resolve the query.
The internals of partition pruning
We create virtual table definition from partitioning description: (part_field1, ... part_fieldN, subpart_field1,...subpart_fieldN)
Rub Range Analyzer over the WHERE clause and the virtual table definition.
Obtain and interval sequence over virtual table definition.
Suppose we have range [a,b] from 2 to 5. The range optimizer can produce a sequence. We walk through all paritions and we see how it overlaps.
Equality propagation (5.0)
SARGable argument transitive closure
What's coming:
- Subquery optimizations (5.2)
- Applied to subquerues in the WHERE clause
- Flattening through semi-joins
- Use hash semi-join when can't flatten
- Batched multiple range (MRR)
- IMplemented for NDB (5,1)
- Coming soon for MyISAM / InnoDB
- Hash join (one-pass; multi-pass)
- Loose index scan for equality conditions
- ORDER BY with LIMIT
Tuesday, April 25, 2006
Scale Out Panel
I am at the scale out panel where DBA gurus from Technorati, MySQL (Brian Aker), Google and Yahoo! are answering questions about scaling.
Some Windows based sites are storing up to 30-40 TB of data using MyISAM tables. That site is masochist.com (joke)
A question was asked whether the date in database should be stored as formatted or stored as time only and then formatted by application. The answer given was (the room was jam packed so I couldn't see the faces) that optimization like this should be done at the end. At first, you should try to add indexes where ever needed. Once all the indexes have been added, only then we should move with other smaller optimizations.
Power consumption having effect on business as you scale out?
There is power, power per watt etc. Power is huge concern for us (Technorati).
Some CPUs use a lot less power than others. At Yahoo! and Google, power is a major concern. We have to find machine that use less power (may be slower disk seeks) and slower CPUs that use less power. Power consumption is a huge issue but only for very large organizations (Yahoo!).
When we went to add some more servers, we weren't being given a data strip because they were out and we have run into such problems.
Load balancing and RAIDs based implementations are easier to scale out.
64bit gives more memory to InnoDB with less power consumption. Use it if at all possible.
Update: Thank you Brian for pointing out that it was TB, not GB. It was a typo on my part that I have corrected.
Some Windows based sites are storing up to 30-40 TB of data using MyISAM tables. That site is masochist.com (joke)
A question was asked whether the date in database should be stored as formatted or stored as time only and then formatted by application. The answer given was (the room was jam packed so I couldn't see the faces) that optimization like this should be done at the end. At first, you should try to add indexes where ever needed. Once all the indexes have been added, only then we should move with other smaller optimizations.
Power consumption having effect on business as you scale out?
There is power, power per watt etc. Power is huge concern for us (Technorati).
Some CPUs use a lot less power than others. At Yahoo! and Google, power is a major concern. We have to find machine that use less power (may be slower disk seeks) and slower CPUs that use less power. Power consumption is a huge issue but only for very large organizations (Yahoo!).
When we went to add some more servers, we weren't being given a data strip because they were out and we have run into such problems.
Load balancing and RAIDs based implementations are easier to scale out.
64bit gives more memory to InnoDB with less power consumption. Use it if at all possible.
Update: Thank you Brian for pointing out that it was TB, not GB. It was a typo on my part that I have corrected.
PHP 5 Upgrade
Laura Thompson, author of several books and director of OmniTI, today presented a session about PHP5 Upgrade: Why and How at MySQL Users Conferece.
Mike Hillyer provides us a thorough summary of the session at his blog. Kristian Kohntopp wrote another summary post about how and why to upgrade to PHP5.
Thanks to Laura for putting the session slides online as well.
I wish all session slides were made available online as the conference is going on. I tried to download slides in the morning from oriellynet.com but they weren't available.
Mike pointed out a MySQL's press release announcing that on Sun, MySQL runs much faster (60 to 90 percent) than on Linux. I agree with Mike that its kind of unfair to compare with Linux on Sun hardware. He proposes an alternative, relatively fairer benchmarking suggestion.
Mike Hillyer provides us a thorough summary of the session at his blog. Kristian Kohntopp wrote another summary post about how and why to upgrade to PHP5.
Thanks to Laura for putting the session slides online as well.
I wish all session slides were made available online as the conference is going on. I tried to download slides in the morning from oriellynet.com but they weren't available.
Mike pointed out a MySQL's press release announcing that on Sun, MySQL runs much faster (60 to 90 percent) than on Linux. I agree with Mike that its kind of unfair to compare with Linux on Sun hardware. He proposes an alternative, relatively fairer benchmarking suggestion.
MySQL Replication New Features
I had lunch and great conversation with Harrison Fisk of MySQL over lunch.
Then I chatted with Jan (lighttpd) again for about half an hour about Ruby, PHP, Rails and of course Apache and Lighttpd. After chatting with Jan I chatted some more with Jeremy Cole of Yahoo!.
Mike gave me a good tip to meet everyone I have been wanting to meet, but unfortunately once again, I didn't check the email until the lunch session was finished.
Right now I am sitting in the MySQL replication new features session.
The new features in MySQL 5.0 include auto-increment variables for bi-directional replication (multi-master).
Starting with MySQL 5, we can have replication of variables such as FOREIGN_KEY_CHECKS, UNIQUE_KEY_CHECKS, SQL_AUTO_IS_NULL and SQL_MODE
Also, character set and time zone replication is now possible.
In addition, replication of stored procedures can now be done.
Auto-increment variables for bi-directional replication (multi-master)
We want two servers to own the information (multi-master replication) for different types of queries on both servers.
Q: Is there a programmatic interface to access the bin log?
A: not really
Q: WHat are the advantages of row based replication (RBR)?
A: We can replicate non-deterministric statements, for example, UDFs, LOAD_FILE(), UUID(), USER(), FOUND_ROWS()
It also makes it possible to replicate between MySQL clusters.
Statement based technology
- it is proven technology
- sometimes (not always) produces smaller log files
There are four new binlog events
1. Table map event: that is mapping of number to table definition so we can find which number matches which table definition.
2. Binwrite event (after image) so "this row shall exist in slave database"
3. Binupdate event (before image, after image) so "this row shall be changed in slave database"
4. Bindelete event (before image) so "this row shal not exist in the slavbe database"
Some optimization tips:
only primary key in BI which will work only if table have PK
Only changed column values in the AI. Works only if table have PK.
Also note that log is idempotent if PK exists and there are only RBR events in log. One more thing to note is that slave can execute both SBR and RBR events.
Tags: mysqluc
Then I chatted with Jan (lighttpd) again for about half an hour about Ruby, PHP, Rails and of course Apache and Lighttpd. After chatting with Jan I chatted some more with Jeremy Cole of Yahoo!.
Mike gave me a good tip to meet everyone I have been wanting to meet, but unfortunately once again, I didn't check the email until the lunch session was finished.
Right now I am sitting in the MySQL replication new features session.
The new features in MySQL 5.0 include auto-increment variables for bi-directional replication (multi-master).
Starting with MySQL 5, we can have replication of variables such as FOREIGN_KEY_CHECKS, UNIQUE_KEY_CHECKS, SQL_AUTO_IS_NULL and SQL_MODE
Also, character set and time zone replication is now possible.
In addition, replication of stored procedures can now be done.
Auto-increment variables for bi-directional replication (multi-master)
We want two servers to own the information (multi-master replication) for different types of queries on both servers.
Q: Is there a programmatic interface to access the bin log?
A: not really
Q: WHat are the advantages of row based replication (RBR)?
A: We can replicate non-deterministric statements, for example, UDFs, LOAD_FILE(), UUID(), USER(), FOUND_ROWS()
It also makes it possible to replicate between MySQL clusters.
Statement based technology
- it is proven technology
- sometimes (not always) produces smaller log files
There are four new binlog events
1. Table map event: that is mapping of number to table definition so we can find which number matches which table definition.
2. Binwrite event (after image) so "this row shall exist in slave database"
3. Binupdate event (before image, after image) so "this row shall be changed in slave database"
4. Bindelete event (before image) so "this row shal not exist in the slavbe database"
Some optimization tips:
only primary key in BI which will work only if table have PK
Only changed column values in the AI. Works only if table have PK.
Also note that log is idempotent if PK exists and there are only RBR events in log. One more thing to note is that slave can execute both SBR and RBR events.
Tags: mysqluc
PHP: A Look at New and Cool Things in the World of PHP
I am sitting in Rasmus Lerdorf's session "A Look at New and Cool Things in the World of PHP". Rasmus is the creator of PHP and works for Yahoo!. He just arrived from Croatia and will be leaving Santa Clara one hour after this session ends.
The session is very informative as I haven't been playing with PHP5 ever since my migration to Ruby on Rails. A lot of exciting developments and changes have been made to PHP. If you are using a PHP application and still running PHP4, you really need to upgrade as soon as possible.
Rasmus says he hates SOAP and isn't going to talk about them a lot. He prefers REST based services.
The top search on Yahoo! was Wikipedia.
Yahoo! has released some new libraries for presenting images with Javascripts.
See the image presentation he created using Yahoo! search at Buzz.ProgPHP.com
Now he is talking about using Yahoo's APIs including Map Tiles APIs.
It's interesting to see Rasmus's interest in Flash.
Rasmus is giving a brief crash course in AJAX with PHP. Everything is presenting is really awesome if I hadn't been introduced to Ruby on Rails.
Now we are back to using Yahoo's UI libraries.
Rasmus gave a minute for questions and answers since he has to leave.
Conference session slides and materials are available at
Getting Rich with PHP
APC: http://pecl.php.net/package/APC
YDN: http://developer.yahoo.net
The session is very informative as I haven't been playing with PHP5 ever since my migration to Ruby on Rails. A lot of exciting developments and changes have been made to PHP. If you are using a PHP application and still running PHP4, you really need to upgrade as soon as possible.
Rasmus says he hates SOAP and isn't going to talk about them a lot. He prefers REST based services.
The top search on Yahoo! was Wikipedia.
Yahoo! has released some new libraries for presenting images with Javascripts.
See the image presentation he created using Yahoo! search at Buzz.ProgPHP.com
Now he is talking about using Yahoo's APIs including Map Tiles APIs.
It's interesting to see Rasmus's interest in Flash.
Rasmus is giving a brief crash course in AJAX with PHP. Everything is presenting is really awesome if I hadn't been introduced to Ruby on Rails.
Now we are back to using Yahoo's UI libraries.
Rasmus gave a minute for questions and answers since he has to leave.
Conference session slides and materials are available at
Getting Rich with PHP
APC: http://pecl.php.net/package/APC
YDN: http://developer.yahoo.net
Bootstrapping: MySQL Users Conference
I just came out of a keynote session by Greg Gianforte, CEO of RightNow Technologies about "Bootstrapping: Starting an Open Source Business with Almost No Money!"
My raw notes (more to come)
1. call lots of people and talk about the issues to them
2. fax or email your idea to 300 people and talk to them
3. build a prototype and personally start selling. [first start selling yourself]
4. after finding a prospect: sell
5. advertising budget is already committed.
6. D&B is asking for company info and detailed financial data. Respectfully refuse.
7. just starting out and not an office that can acommodate
8 how many people in the business if working alone? 5 people (accountant, spouse etc.
Overall, a great session with lots of tips.
Also see:
MySQL UC Opening Keynote report
Bootstrapping session notes by Ronald
Many congratulations to Roland and Markus for receiving community awards at the morning keynote session.
Yesterday, I got to meet Arjen Lentz, Jeremy Cole, Colin Charles, Kaj Arnö, Peter and Tobias in person at the MySQL speakers reception. In addition, I met Jan, the creator of Lighttpd and Greg of CleverSafe. Jan told me the correct way to pronounce Lighttpd is "lighty". I had a great time asking Jan a lot of questions about why and how to migrate to lighty from Apache.
I am really trying to find some friends here at MySQL UC especially Jay Pipes, Sheeri Kritzer, Markus, Ronald, Roland and everyone contributing to PlanetMySQL, but so far no luck. Sheeri was lucky in finding some of them but I am still trying. Sheeri's photos helped me spot who's wearing what so I can look for everyone (Thanks Sheeri).
If you are at the conference and spot me, stop me and say hi. My conference badge says my real name "Farhan Mashraqi". I look forward to seeing you.
Frank
Tag: MySQLUC
My raw notes (more to come)
1. call lots of people and talk about the issues to them
2. fax or email your idea to 300 people and talk to them
3. build a prototype and personally start selling. [first start selling yourself]
4. after finding a prospect: sell
5. advertising budget is already committed.
6. D&B is asking for company info and detailed financial data. Respectfully refuse.
7. just starting out and not an office that can acommodate
8 how many people in the business if working alone? 5 people (accountant, spouse etc.
Overall, a great session with lots of tips.
Also see:
MySQL UC Opening Keynote report
Bootstrapping session notes by Ronald
Many congratulations to Roland and Markus for receiving community awards at the morning keynote session.
Yesterday, I got to meet Arjen Lentz, Jeremy Cole, Colin Charles, Kaj Arnö, Peter and Tobias in person at the MySQL speakers reception. In addition, I met Jan, the creator of Lighttpd and Greg of CleverSafe. Jan told me the correct way to pronounce Lighttpd is "lighty". I had a great time asking Jan a lot of questions about why and how to migrate to lighty from Apache.
I am really trying to find some friends here at MySQL UC especially Jay Pipes, Sheeri Kritzer, Markus, Ronald, Roland and everyone contributing to PlanetMySQL, but so far no luck. Sheeri was lucky in finding some of them but I am still trying. Sheeri's photos helped me spot who's wearing what so I can look for everyone (Thanks Sheeri).
If you are at the conference and spot me, stop me and say hi. My conference badge says my real name "Farhan Mashraqi". I look forward to seeing you.
Frank
Tag: MySQLUC
Monday, April 24, 2006
MySQL Performance Tuning
I am right now sitting in Introduction to MySQL Performance Tuning by Tobias.
Re-executing a command
We can use the -r option to re-execute a command.
For instance:
mysqladmin -ri 10 extended
will execute the command every 10 seconds
Open tables is the size of table cache.
Threads cached is caching of threads. When someone disconnects, we don't just throw it away.
If we have multiple queries at the same time, the number of tables opened will go up.
Brad of Live Journal has written a cool script called diskchecker.pl
Analyzing queries: Use the slow query log to obtain information about well, slow queries. One idea is to log all queries to CSV tables and then use them.
When enabling or disabling the slow queries log, we need to restart the server. By default the slow query log logs all those queries that take more than 10 seconds to execute.
A problem with slow query logs is that it does not tells us about the queries most frequently executed.
Tip: Get the regular expression from mysqldumpslow
If the difference between rows sent and rows examined is huge, we can add an index to the table.
If we need to obtain the information without having to get it through the slow queries log, we can use the EXPLAIN statement.
In the EXPLAIN statement, we have the following types of type:
Re-executing a command
We can use the -r option to re-execute a command.
For instance:
mysqladmin -ri 10 extended
will execute the command every 10 seconds
Open tables is the size of table cache.
Threads cached is caching of threads. When someone disconnects, we don't just throw it away.
If we have multiple queries at the same time, the number of tables opened will go up.
Brad of Live Journal has written a cool script called diskchecker.pl
Analyzing queries: Use the slow query log to obtain information about well, slow queries. One idea is to log all queries to CSV tables and then use them.
When enabling or disabling the slow queries log, we need to restart the server. By default the slow query log logs all those queries that take more than 10 seconds to execute.
A problem with slow query logs is that it does not tells us about the queries most frequently executed.
Tip: Get the regular expression from mysqldumpslow
If the difference between rows sent and rows examined is huge, we can add an index to the table.
If we need to obtain the information without having to get it through the slow queries log, we can use the EXPLAIN statement.
In the EXPLAIN statement, we have the following types of type:
- (system): if table has one row.
- const:
- eq_ref
- ref
- index_merge
- unique_subquery / index_subquery
- range
- index
- all
Fixing and Tuning Indexes
BTREE is always balanced. No other way to see whether index tree is balanced.
If we have redundant indexes, disk usage will go up and we will be wasting the buffer cache.
How do I see whether there are multiple (redundant) indexes created on a table
SHOW INDEX FROM ...
SHOW CREATE TABLE
For large columns that we need to have unique, it is better to store a hash value.
Data types such as VARCHAR take more space both in memory and on disk. Both VARCHAR (20) AND VARCHAR (255) will take same amount of space for small data sizes. This is because when a row is read up into memory, fixed memory buffer sizes are used. In addition, MEMORY tables use fixed size rows.
Q: Find the minimum and maximum length of the data in a table.
A: Use the PROCEDURE ANALYSE() option as in SELECT fieldname FROM table PROCEDURE ANALYSE
more soon...
Optimizing MySQL Applications Using the Pluggable Storage Engine Architecture (Arjen)
I am sitting in Arjen's session titled "Optimizing MySQL Applications Using the Pluggable Storage Engine Architecture." Arjen has been covering the basics of how databases work and touching up on issues related to different storage engines.
[Notes that I need to transfer (blogger wasn't working)]
Key Buffers: Are only for MyISAM tables and not for InnoDB tables. Look at the current values
Key reads / Key read requests ratio should be 0.03. If the ratio is higher than this (.10) then increase the buffer. If its better than this (0.1) then we are wasting memory. If at 0.1, decrease it a bit.
The default settings are quite low on Linux. We can have multiple MyISAM key caches.
We can load MySQL key buffers into memory.
Different values of myisam_recover which can either be QUICK or BACKUP (If some corrupted tables are found, they are first backed up).
Arjen recommends that not to use external locking and then repair the table (answering a question). He says to lock tables using LOCK command and then perform operations.
table_cache (defaults to 64). This deals with file handles which tells the maximum number of open table files. If joining three tables, three MYD files would be opened. Even if we join the same table, two files would be opened so a pointer can be obtained.
myisam_sort_buffer_size: increase this for index builds. A trick is to increase and decrease it again when not needed.
myisam_max_[extra]_sort_file_size: By increasing this we can speed things up.
MyISAM local variables: allocated for each individual connection to the server.
read_buffer_size: used when reading chunk of data. Get this to be as big as we can afford to have. Think about altering it before SELECTs and then decrease it to original as this will be local.
sort_buffer_size: For GROUP BY and ORDER BY operations. If MySQL needs more value than this then it will start using disk (bad). Increase sort buffer before query and then decrease it.
tmp_table_size: It's a limit in bytes. While processing queries, tmp tables are created which are of type HEAP. When we run out of the specified size set by this variable, the table type is changed from HEAP to MyISAM.
Make the local variables bigger than default but don't make them huge.
Never make your database server swap as it will cost you greatly.
How to optimize MyISAM tables?
Avoid NULLS and declare the columns to be NOT NULLs whenever possible.
Inside MyISAM structure we waste resources when using NULLs as many IF statements that are used to check whether the value is NULL can add up.
When performing batch deletes, updates, inserts, consider first disabling indexes and then enabling them.
Q & A: myisamchk updates the table stats when it runs.
MERGE
Its not really a separate storage engine but instead a layer.
Why use MERGE tables?
Because of the filesystem limits. To store big tables, they must be splitted up to keep them manageable. That's when MERGE tables come in.
MERGE tables are very portable and their files can just be copied over. We can only perform SELECT, DELETE, UPDATE and INSERT statements when using MERGE tables.
We need more file descriptors which is a disadvantage. Also the index reads are slower and no global indexes are available.
MEMORY storage engine.
Only the structure of MEMORY tables (.FRM) is stored on disk. Data is volatile since it resides in RAM. MEMORY tables feature table locks. The size of MEMORY tables is specified using max_heap_table_size. Using a trigger, we can automatically change the table type from MEMORY to MyISAM using COUNT(). MEMORY tables are used primarily for caching, temporary tables and buffer tables. The primary options for indexing MEMORY tables are HASH (Hash Indexes) and BTREE (Red-black binary trees). Important to note that BTREE here isn't the same as BTREE used for MyISAM tables.
BTREE takes more space, supports range searches and is faster in cases where we have lots of duplicates.
HASH index is used by MEMORY tables by default.
InnoDB Storage Engine: It is transactional, ACID, supports foreign key constraints and performs data checksums to verify its integrity.
Has row level locking with versioning. Larger memory and on disk footprint. MySQL 5 has data compression. Likes more memory and if enough memory is given, it is pretty much equal in performance than MyISAM. In certain cases we can make InnoDB faster than MyISAM but that would require a lot of RAM.
It is good for apps with heavy updates. In case of server crash, the repairing is done automatically by InnoDB in the background. For primary keys, it offers faster access by primary keys and is better in memory performance. ALso offers row-level locking (SELECTs don't LOCK).
For InnoDB , always have PRIMARY key as short as possible (don't use VARCHAR). Even CHAR(30) is really really bad.
Transactions are run in memory. InnoDB knows the difference between committed and uncommitted page.
innodb_buffer_pool_size: set to as large as possible (think 60-80% of unused memory).
In write intensive system, have a large buffer pool.
innodb_log_files_group: (used to be 3)
innodb_log_file_size specifies the size of each log file. Setting it too high will increase the time that goes in crash recovery. Recommended to set it to 50% of innodb_buffer_pool_size.
innodb_log_buffer_size: Recommended to set between 1M and 16M (default: 8MB)
innodb_flush_method: by default it uses fsync()
innodb _thread_concurrency: number of threads running in the background.
InnoDB Performance:
If possible, insert in the order of primary keys.
Sort the data externally before loading/inserting it in InnoDB
Can optionally set FOREIGN_KEY_CHECKS=0 (risky)
Use Prefix keys i.e. INDEX (lastname(3)) to optimize (relatively new in InnoDB). This feature works with MyISAM too.
NDB Cluster Storage Engine: (Not a general purpose storage engine, redundant and very fast for some purposes)
Designed for high availability and scalability (if used with load balancing). NDB Cluster Storage Engine also features synchronous replication and two-phase commit (can we commit?). Only commits when everything is ready. Performs internal replication and distributes table to several nodes. Offers multiple ways to be fast and redundant.
FEDERATED Storage Engine:
Offers the ability to access remote MySQL servers as if they were local. Very useful when using with triggers. MySQL is looking at offering hetrogeneous connectivity in future using JDBC for Federated tables.
ARCHIVE Storage Engine: If data is more than 1.5 GB then the table scans are much faster than MyISAM. ARCHIVE Storage engine is recommended for logging, auditing and backups. All data stored is compressed using zlib and offers sequential storage. We can only insert and select (performed using full table scans).
Any engine can be replicated.
CSV Storage Engine is not a general purpose storage engine. Ideal for storing CSV files.
Overall a great session. I will be adding more notes and clarifying the above points as I get time ;)
[Notes that I need to transfer (blogger wasn't working)]
Key Buffers: Are only for MyISAM tables and not for InnoDB tables. Look at the current values
Key reads / Key read requests ratio should be 0.03. If the ratio is higher than this (.10) then increase the buffer. If its better than this (0.1) then we are wasting memory. If at 0.1, decrease it a bit.
The default settings are quite low on Linux. We can have multiple MyISAM key caches.
We can load MySQL key buffers into memory.
Different values of myisam_recover which can either be QUICK or BACKUP (If some corrupted tables are found, they are first backed up).
Arjen recommends that not to use external locking and then repair the table (answering a question). He says to lock tables using LOCK command and then perform operations.
table_cache (defaults to 64). This deals with file handles which tells the maximum number of open table files. If joining three tables, three MYD files would be opened. Even if we join the same table, two files would be opened so a pointer can be obtained.
myisam_sort_buffer_size: increase this for index builds. A trick is to increase and decrease it again when not needed.
myisam_max_[extra]_sort_file_size: By increasing this we can speed things up.
MyISAM local variables: allocated for each individual connection to the server.
read_buffer_size: used when reading chunk of data. Get this to be as big as we can afford to have. Think about altering it before SELECTs and then decrease it to original as this will be local.
sort_buffer_size: For GROUP BY and ORDER BY operations. If MySQL needs more value than this then it will start using disk (bad). Increase sort buffer before query and then decrease it.
tmp_table_size: It's a limit in bytes. While processing queries, tmp tables are created which are of type HEAP. When we run out of the specified size set by this variable, the table type is changed from HEAP to MyISAM.
Make the local variables bigger than default but don't make them huge.
Never make your database server swap as it will cost you greatly.
How to optimize MyISAM tables?
- Normalize
- separate static and dynamic storage format tables. (don't worry about joins as databases are made for that)
Avoid NULLS and declare the columns to be NOT NULLs whenever possible.
Inside MyISAM structure we waste resources when using NULLs as many IF statements that are used to check whether the value is NULL can add up.
When performing batch deletes, updates, inserts, consider first disabling indexes and then enabling them.
Q & A: myisamchk updates the table stats when it runs.
MERGE
Its not really a separate storage engine but instead a layer.
Why use MERGE tables?
Because of the filesystem limits. To store big tables, they must be splitted up to keep them manageable. That's when MERGE tables come in.
MERGE tables are very portable and their files can just be copied over. We can only perform SELECT, DELETE, UPDATE and INSERT statements when using MERGE tables.
We need more file descriptors which is a disadvantage. Also the index reads are slower and no global indexes are available.
MEMORY storage engine.
Only the structure of MEMORY tables (.FRM) is stored on disk. Data is volatile since it resides in RAM. MEMORY tables feature table locks. The size of MEMORY tables is specified using max_heap_table_size. Using a trigger, we can automatically change the table type from MEMORY to MyISAM using COUNT(). MEMORY tables are used primarily for caching, temporary tables and buffer tables. The primary options for indexing MEMORY tables are HASH (Hash Indexes) and BTREE (Red-black binary trees). Important to note that BTREE here isn't the same as BTREE used for MyISAM tables.
BTREE takes more space, supports range searches and is faster in cases where we have lots of duplicates.
HASH index is used by MEMORY tables by default.
InnoDB Storage Engine: It is transactional, ACID, supports foreign key constraints and performs data checksums to verify its integrity.
Has row level locking with versioning. Larger memory and on disk footprint. MySQL 5 has data compression. Likes more memory and if enough memory is given, it is pretty much equal in performance than MyISAM. In certain cases we can make InnoDB faster than MyISAM but that would require a lot of RAM.
It is good for apps with heavy updates. In case of server crash, the repairing is done automatically by InnoDB in the background. For primary keys, it offers faster access by primary keys and is better in memory performance. ALso offers row-level locking (SELECTs don't LOCK).
For InnoDB , always have PRIMARY key as short as possible (don't use VARCHAR). Even CHAR(30) is really really bad.
Transactions are run in memory. InnoDB knows the difference between committed and uncommitted page.
innodb_buffer_pool_size: set to as large as possible (think 60-80% of unused memory).
In write intensive system, have a large buffer pool.
innodb_log_files_group: (used to be 3)
innodb_log_file_size specifies the size of each log file. Setting it too high will increase the time that goes in crash recovery. Recommended to set it to 50% of innodb_buffer_pool_size.
innodb_log_buffer_size: Recommended to set between 1M and 16M (default: 8MB)
innodb_flush_method: by default it uses fsync()
innodb _thread_concurrency: number of threads running in the background.
InnoDB Performance:
If possible, insert in the order of primary keys.
Sort the data externally before loading/inserting it in InnoDB
Can optionally set FOREIGN_KEY_CHECKS=0 (risky)
Use Prefix keys i.e. INDEX (lastname(3)) to optimize (relatively new in InnoDB). This feature works with MyISAM too.
NDB Cluster Storage Engine: (Not a general purpose storage engine, redundant and very fast for some purposes)
Designed for high availability and scalability (if used with load balancing). NDB Cluster Storage Engine also features synchronous replication and two-phase commit (can we commit?). Only commits when everything is ready. Performs internal replication and distributes table to several nodes. Offers multiple ways to be fast and redundant.
FEDERATED Storage Engine:
Offers the ability to access remote MySQL servers as if they were local. Very useful when using with triggers. MySQL is looking at offering hetrogeneous connectivity in future using JDBC for Federated tables.
ARCHIVE Storage Engine: If data is more than 1.5 GB then the table scans are much faster than MyISAM. ARCHIVE Storage engine is recommended for logging, auditing and backups. All data stored is compressed using zlib and offers sequential storage. We can only insert and select (performed using full table scans).
Any engine can be replicated.
CSV Storage Engine is not a general purpose storage engine. Ideal for storing CSV files.
Overall a great session. I will be adding more notes and clarifying the above points as I get time ;)
MySQL UC: Arriving in San Francisco
Me and my wife arrived safe and sound in San Francisco on Friday afternoon. The flight was long but not too bad. Early in the flight there was a lot of turbulence but the pilot warned us about it.
I have never been to San Francisco and much like Roland, its beauty and landscape swept me from my feet.
After arriving I went straight to Hertz to pick up a car that I had already reserved. Since
they didn't have the car I reserved, they gave me a free upgrade to Sonata, which I must say
is quite a car.
We drove to Monterey, CA to see my sister in law's family. The drive was very scenic. In the
way we saw (but didn't take) the exit for Mountain View, CA (Hint: Google). We were
literally starving by this time as we live about 2 hours away from Atlanta and after being
up since 4:00 AM, I just couldn't think of anything other than food. So we took the next
exit (I don't remember which one) and found an Indian restaurant (Bombay Oven)
with very yummy food. So tasty that I plan to revisit the restaurant, possibly with some of
my friends.
In Monterey, I spent a lovely day and a half. Our host family took us to a lovely hike to
Pfieffer Falls which was just awesome. I must confess that the drive from Monterey to Big
Sur was one of the most scenic drives I have ever been on. My sister in law's husband, Vic,
works for the US Navy and is a very experienced and friendly geek. He has been designing
systems for about 20 years now. He took me on a very special tour of Navy's Post Graduate
College and showed me his office which requires biometric identification.
Today, I went with my wife to the Fisherman's Wharf in Monterey and saw many Sea Lions
sleeping and playing on the ocean. I accidentally forgot my camcorder at home so couldn't record my time there.
Tonight I finally checked in at a hotel in Milpitas, CA. It's only minutes away from the convention center. As soon as we checked in, we decided to get a bite. I was in mood for some wings but after driving for more than 30 minutes, we decided to eat at the Panda Express.
Then I saw a commercial on local TV at my hotel room that actually said the words "Red Hat Linux." I don't remember ever seeing a commercial in GA referencing RHEL so I thought I would note this down.
It was very nice of Roland Bouman to invite me to go with him and Markus Popp to pick Mike
Kruckenberg up from SFO. Unfortunately I got the email really late in the day
and therefore missed the great opportunity to hang out with them which I greatly regret.
In the morning, I will be attending the tutorial by Arjen Lentz, "Optimizing MySQL Applications Using the Pluggable Storage Engine Architecture". Then, I will be attending Peter Zaitsev's MySQL Performance Optimization . I am really looking forward to both of these tutorials.
I will be posting my conference schedule tomorrow evening after the dinner hosted by MySQL.
On Thursday, I will be presenting the Applied Ruby on Rails and AJAX session.
Thank you MySQL, for hosting this conference at such a beautiful place and giving me and others the opportunity to come to California.
I must go to bed now so I can be at the conference on time ;)
-- Frank
Tags: MySQL UC MySQL UC 2006
Thursday, April 20, 2006
Flying to San Francisco
Tomorrow morning around 4, I will be leaving for San Francisco to attend MySQL UC like many of my friends. It will be a very long flight but I am very excited to meet people whom I know by name but not by face.
I am really short of words to thank MySQL for giving me the opportunity to come to SF.
If you are arriving in SF a bit early, please drop me a line and lets plan to get together for dinner or drinks.
Frank
I am really short of words to thank MySQL for giving me the opportunity to come to SF.
If you are arriving in SF a bit early, please drop me a line and lets plan to get together for dinner or drinks.
Frank
Sunday, April 02, 2006
Oh no!
I agree with Markus that closing of Andrew's MySQLDevelopment.com is a really sad news. I hope a way can be found to keep the site alive. I think the best idea would be to make a Wiki like M pointed out.
Frank
Frank
I have a dream!
The bad side effect of working too late on projects is that you end up dreaming about them.
Well, yesterday night when I went to sleep I dreamt that there was a cool favorites badge of the MySQL community posted on Planet MySQL where all the visitors could see favorites posted to the community in real time. The favorites badge would look something like this:
and / or
The benefit of having a badge like this would be that all the passionate MySQL users would build a joint favorites repository that could be tagged and expanded by anyone. It would be really cool to see the latest trends and patterns of such an initiative. One thing is for sure that finding and organizing new resources as they relate to MySQL would be a breeze.
So I woke up today and just couldn't stop myself from building an interface that does just that. The query I used to get the data from the table is provided here (includes some Ruby on Rails code):
The first part of my dream has been realized and it is presented here. Assuming some passionate MySQL users lend me a hand, this badge can be populated in no time. However, before anyone can contribute to a badge like this, they will need to join Adoppt and be a member of the MySQL community (there are only three members at the time of writing, myself, CJ and faeriebell). In addition, a representative of PlanetMySQL will need to create/put the badge code on PlanetMySQL.
I'm not sure how far this idea will go but hey it was a dream and it lead me to add a "collaborative bookmarking badge" feature to Adoppt.
More about the favorites badge feature at Mr. Adoppt's blog. Also see the bookmarklet to quickly bookmark your favorites.
-- Frank
Well, yesterday night when I went to sleep I dreamt that there was a cool favorites badge of the MySQL community posted on Planet MySQL where all the visitors could see favorites posted to the community in real time. The favorites badge would look something like this:
and / or
The benefit of having a badge like this would be that all the passionate MySQL users would build a joint favorites repository that could be tagged and expanded by anyone. It would be really cool to see the latest trends and patterns of such an initiative. One thing is for sure that finding and organizing new resources as they relate to MySQL would be a breeze.
So I woke up today and just couldn't stop myself from building an interface that does just that. The query I used to get the data from the table is provided here (includes some Ruby on Rails code):
Favorite.find_by_sql("SELECT tags.id AS id, tags.name AS name, COUNT(*) AS count FROM tags_favorites, favorites, members, friends_members, tags WHERE tags_favorites.tag_id = tags.id AND tags_favorites.favorite_id = favorites.id AND members.id =#{@user.id} AND friends_members.member_id = members.id AND favorites.member_id = friends_members.friend_id #{p_append} GROUP BY tags.name ORDER BY #{order_string} LIMIT #{num}")
The first part of my dream has been realized and it is presented here. Assuming some passionate MySQL users lend me a hand, this badge can be populated in no time. However, before anyone can contribute to a badge like this, they will need to join Adoppt and be a member of the MySQL community (there are only three members at the time of writing, myself, CJ and faeriebell). In addition, a representative of PlanetMySQL will need to create/put the badge code on PlanetMySQL.
I'm not sure how far this idea will go but hey it was a dream and it lead me to add a "collaborative bookmarking badge" feature to Adoppt.
More about the favorites badge feature at Mr. Adoppt's blog. Also see the bookmarklet to quickly bookmark your favorites.
-- Frank
Subscribe to:
Posts (Atom)