Google Base is Google’s latest project in an effort to organize the world’s information. It isn’t in Beta or Alpha yet. They are still developing it. I wasn’t able to get much information from my sources at Google, but I’ll tell you what they told me. Basically, Google Base will present feed results on the results page. The feeds will probably be anywhere from 1-3 results, and either presented above or below the horizontal sponsored ads. I asked if the feeds will include podcast feeds, or just RSS feeds. My source wasn’t sure. I asked if they be sponsored ads for feeds, or just what Google considers relevant? Answer not known. We’ll just have to wait and see.
At first I thought Google Base may be a new kind of personalized home page. I was wrong. Today I am finding information on Google Base just about everywhere.
Aiming to list everything about *you*, Google Base is Google's direct attack on eBay, Paypal (an eBay company), Craigslist, and thousands of other small websites.
Regarding when exactly Google base will be officially announced, Search Engine Roundtable (SER) had the following to say:
This new tool will be introduced during the 'Google Zeitgeist'05 Partner Forum' to be held today at Google HQ in California. We expect that 'Google Purchases' [hey, I spotted that domain two weeek's ago] --the new micropayments service among users-- will be also introduced as a complement to 'Google Base'.
On its official Google Blog, the following was posted by Tom Oliveri, Product Marketing Manager, Google Inc.
You may have seen stories today reporting on a new product that we're testing, and speculating about our plans. Here's what's really going on. We are testing a new way for content owners to submit their content to Google, which we hope will complement existing methods such as our web crawl and Google Sitemaps. We think it's an exciting product, and we'll let you know when there's more news.
Google is, IMO, crossing the line here by becoming a content publisher itself. Mom and Pop websites online have been hit very hard by Google's unjustified penalties. From what I see, and as confirmed by Google's SEC filings, Google thinks of pretty much everyone as a competitor, even its own partners. I know of several innocent webmasters who, after having years of success with Google, were penalized to the point that they simply closed down their operations. First Google went after directory sites, then travel sites, then shopping sites, then affiliate sites, and now every auction service provider is going to be considered a scraper or a content provider that "adds little or no original value." It's also interesting to note the timing with which Google penalizes innocent websites. For e.g., right at the beginning of the travel season, travel sites are dropped. Right before the shopping season, shopping sites are dropped (two years in a row). It will not end here.
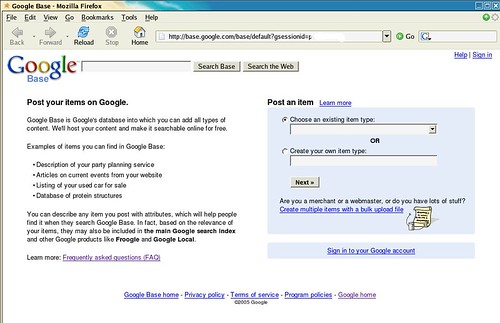
Screenshots Courtesy: Dirson/Flickr
But Google Base is not the only project Google is up to. Andrew Hitchcock posted on his blog about Jeffrey Dean's talk on BigTable. In his post, Andrew writes:
BigTable has been in development since early 2004 and has been in active use for about eight months (about February 2005). There are currently around 100 cells for services such as Print, Search History, Maps, and Orkut. Following Google's philosophy, BigTable was an in-house development designed to run on commodity hardware. BigTable allows Google to have a very small incremental cost for new services and expanded computing power (they don't have to buy a license for every machine, for example). BigTable is built atop their other services, specifically GFS, Scheduler, Lock Service, and MapReduce.
Each table is a multi-dimensional sparse map. The table consists of rows and columns, and each cell has a time version. There can be multiple copies of each cell with different times, so they can keep track of changes over time. In his examples, the rows were URLs and the columns had names such as "contents:" (which would store the file data) or "language:" (which would contain a string such as "EN").
In order to make each [tablet] manage the huge tables, the tables are split at row boundaries and saved as tablets. Tablets are each around 100-200 MB and each machine stores about 100 of them (they are stored in GFS). This setup allows fine grain load balancing (if one tablet is receiving lots of queries, it can shed other tablets or move the busy tablet to another machine) and fast rebuilding (when a machine goes down, other machines take one tablet from the downed machine, so 100 machines get new tablet, but the load on each machine to pick up the new tablet is fairly small).
Tablets are stored on systems as immutable SSTables and a tail of logs (one log per machine). When system memory is filled, it compacts some tablets. He went kind of fast through this, so I didn't have time to write everything down, but here is the overview: There are minor and major compactions. Minor compactions involve only a few tablets, while major ones involve the whole system. Major compactions can reclaim hard disk space. The location of the tablets are actually stored in special BigTable cells. The lookup is a three-level system. The clients get a pointer to the META0 tablet (there is only one). This tablet is heavily used, and so one machine usually ends up shedding all its other tablets to support the load. The META0 tablet keeps track of all the META1 tablets. These tables contain the location of the actual tablet being looked up. There is no big bottleneck in the system, because they make heavy use of pre-fetching and caching.
Back to columns. Columns are in the form of "family:optional_qualifier". In his example, the row "www.cnn.com" might have the columns "contents:" with the HTML of the page, "anchor:cnn.com/news" with the anchor text of that link ("CNN Homepage"), and "anchor:stanford.edu/" with that anchor text ("CNN"). Columns have type information. Columns families can have attributes/rules that apply to their cells, such as "keep n time entries" or "keep entries less than n days old". When tablets are rebuilt, these rules are applied to get rid of any expired entries. Because of the design of the system, columns are easy to create (and are created implicitly), while column families are heavy to create (since you specify things like type and attributes). In order to optimize access, column families can be split into locality groups. Locality groups cause the columns to be split into different SSTables (or tablets?). This increases performance because small, frequently accessed columns can be stored in a different spot than the large, infrequent columns.
All the tablets on one machine share a log; otherwise, one million tablets in a cluster would result in way too many files opened for writing (there seems to be a discrepancy here, he said 100 tablets per machine and 1000 machines, but that doesn't equal one million tablets). New log chunks are created every so often (like 64 MB, which would correspond with the size of GFS chunks). When a machine goes down, the master redistributes its log chunks to other machines to process (and these machines store the processed results locally). The machines that pick up the tablets then query the master for the location of the processed results (to update their recently acquired tablet) and then go directly to the machine for their data.
There is a lot of redundant data in their system (especially through time), so they make heavy use of compression. He went kind of fast and I only followed part of it, so I'm just going to give an overview. Their compression looks for similar values along the rows, columns, and times. They use variations of BMDiff and Zippy. BMDiff gives them high write speeds (~100MB/s) and even faster read speeds (~1000MB/s). Zippy is similar to LZW. It doesn't compresses as highly as LZW or gzip, but it is much faster. He gave an example of a web crawl they compressed with the system. The crawl contained 2.1B pages and the rows were named in the following form: "com.cnn.www/index.html:http". The size of the uncompressed web pages was 45.1 TB and the compressed size was 4.2 TB, yielding a compressed size of only 9.2%. The links data compressed to 13.9% and the anchors data compressed to 12.7% the original size.
They have their eye on the future with some features under consideration. 1. Expressive data manipulation, including having scripts sent to clients to modify data. 2. Multi-row transaction support. 3. General performance for larger cells. 4. BigTable as a service. It sounds like each service (such as Maps or Search History) have their own cluster running BigTable. They are considering running a Google-wide BigTable system, but that would require fairly splitting resources and compute time, etc.
From the screenshots provided by Dirson,
Examples of items you can find in Google Base:
- Description of your party planning service
- Articles on current events from your website
- Listing of your used car for sale
- Database of protein structures
Interestingly, when I tried to login using my Google account, I was continously kicked back to the login page to confirm my password. Needless to say, I stopped trying.
Philipp Lenssen posted on his blog:
This sounds big and immensely interesting. Is Google putting a layer in-between dynamic web sites and their databases, replacing MySQL/PostgreSQL/MS SQL, and creating a new GoogleSQL... possibly, with their ads in it? I can’t wait to try it.
GoogleSQL? Whoa! Only time will tell.
Now that Google is coming into MySQL's domain, isn't it time for MySQL to jump in to Google's domain? If I was consulting MySQL AB (yes I provide consulting services), I would definitely urge MySQL AB to start a search service. If MySQL won't, Oracle may. Knowing the loyalty and passion of MySQL community, there is no doubt in my mind that should MySQL jump in to the search industry, their results will be far better and relevant than Google.
2 comments:
At the current gbase state it's impossible to pose a real threat to any db product in the market, this is due to the annoying stochatics queries in google base.
Yeap, what u r reading is correct: if you create custom types with custom attributes, google doesnt index those attributes in a deterministic way, so sometimes you get after querying 20 items, a day after 12, an hour later 23 and so on...
This happens in your private -and- public feeds...
:(
that is realy great article ,helping to know about depths of Mysql, thanks for it
http://mysqlexamples.blogspot.com/
Post a Comment